
Amazon AWS Summit Madrid 2017: un breve resoconto dell'evento
Questo post vuole essere un breve resoconto del Summit di Amazon AWS 2017, svoltosi a Madrid il 21 settembre, ultima tappa europea del tour mondiale di Amazon. L’afflusso di gente intervenuta è stato a dir poco esorbitante, creando a volte disagi negli spostamenti o nell’ascoltare la persona che si aveva di fronte. L’evento ha avuto inizio con il keynote del vice presidente strategie architettura Cloud AWS Adrian Cockcroft, che ha illustrato la crescita dell’azienda nell’ultimo anno in termini di numero di clienti/partner e nuovi servizi offerti (alcuni milioni di clienti distribuiti in 190 paesi e più di 1.000 nuovi servizi/funzionalità introdotte nel 2016).


Sono intervenuti successivamente Miguel Alava, direttore di AWS, e Carina Szpilka, fondatrice di K Fund VC e presidente di Adigital, che hanno sottolineato l’importanza della digitalizzazione nel mercato spagnolo, sebbene solo un’impresa su tre sia al momento preparata all’introduzione di nuove tecnologie.

Nel pomeriggio si sono svolte le sessioni relative ad alcuni temi specifici. Avendo dovuto effettuare una scelta, in quanto le differenti sessioni si svolgevano contestualmente, ho deciso di prendere parte agli incontri relativi ai Big Data e alla IA. Il primo intervento ha riguardato, per l’appunto, i Big Data. Ma cosa s’intende con questo termine? I Big Data possono essere descritti in termini di gestione dei dati: a causa dell’aumento del volume, della velocità e della varietà dei dati, alcune sfide non possono essere risolte con i database tradizionali. Anche se i Big Data possono essere definiti in molti modi, la maggior parte include le tre V: Volume (è incluso tra i terabyte e i petabyte di dati), Varietà (i dati provengono da un’ampia gamma di sorgenti e si presentano in diversi formati, ad esempio log Web, interazioni su social media, transazioni online e di e-commerce, transazioni finanziarie e così via), Velocità (le aziende hanno requisiti e scadenze sempre più stringenti, dal momento in cui i dati vengono generati a quello in cui analisi fruibili vengono inviate agli utenti. Di conseguenza, i dati devono essere raccolti, salvati, elaborati e analizzati a scadenze molto brevi, dalla giornata al tempo reale). Avendone dato una definizione, come spiegare il loro funzionamento? Grazie a nuovi strumenti che sono in grado di gestire l’intero ciclo di vita dei dati, le tecnologie collegate ai Big Data rendono possibile (tecnicamente ed economicamente) non solo la raccolta e la memorizzazione di set di dati di grandi dimensioni, ma anche la relativa analisi, consentendo di estrapolarne informazioni preziose. Nella maggior parte dei casi, l’elaborazione di Big Data interessa un flusso di dati comune, dalla raccolta di dati grezzi alla creazione di analisi concrete. La raccolta di dati grezzi (transazioni, log, dispositivi mobili e così via) è la prima sfida da affrontare quando si parla di Big Data. Una buona piattaforma per i Big Data semplifica questo passaggio, consentendo agli sviluppatori di inoltrare un’ampia varietà di dati, sia strutturati sia non strutturati, a qualsiasi velocità, sia in tempo reale sia in batch. Una piattaforma per i Big Data, inoltre, necessita di un repository sicuro, scalabile e durevole in cui memorizzare i dati prima e, talvolta, dopo le attività di elaborazione. A seconda dei requisiti specifici, potrebbe occorrere anche uno storage temporaneo per i dati in transito. Nella fase successiva i dati vengono trasformati: da grezzi vengono convertiti in formato utilizzabile, di norma tramite operazioni di ordinamento e aggregazione e, talvolta, operazioni più complesse quali funzioni avanzate e algoritmi. I set di dati risultanti vengono memorizzati per ulteriori elaborazioni oppure resi disponibili per l’utilizzo in strumenti di business intelligence o di rappresentazione grafica. L’idea dietro ai Big Data è, per l’appunto, quella di ottenere preziose analisi concrete a partire dagli asset disponibili. Idealmente, i dati vengono resi disponibili ai soggetti interessati tramite strumenti di business intelligence e di rappresentazione grafica dei dati che consentono loro di esaminare i set di dati in modo rapido e veloce. A seconda del tipo di analisi, gli utenti finali potrebbero utilizzare i dati come previsioni statistiche (nel caso delle analisi predittive) o provvedimenti che è consigliabile applicare (in caso di analisi prescrittive).
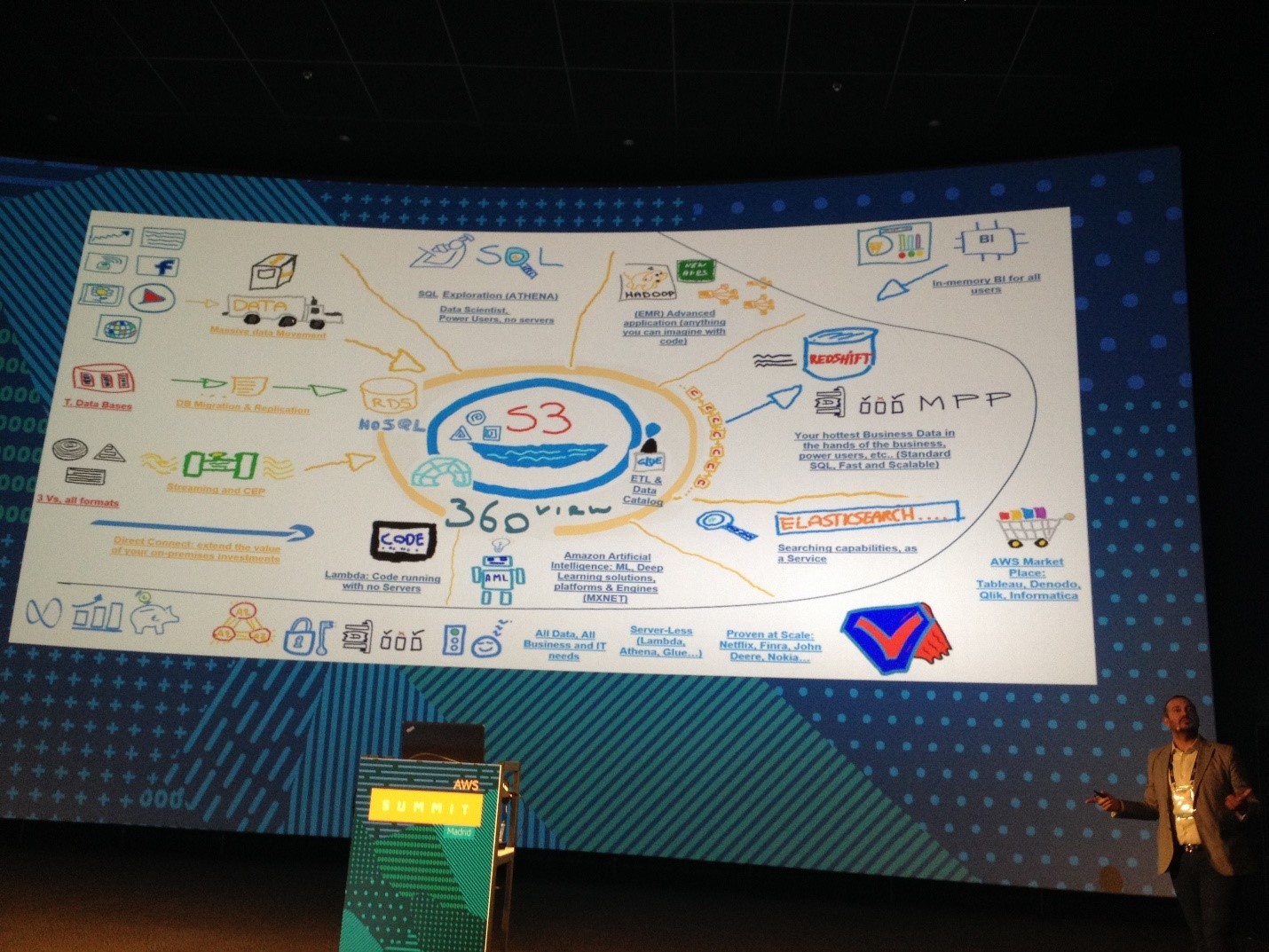
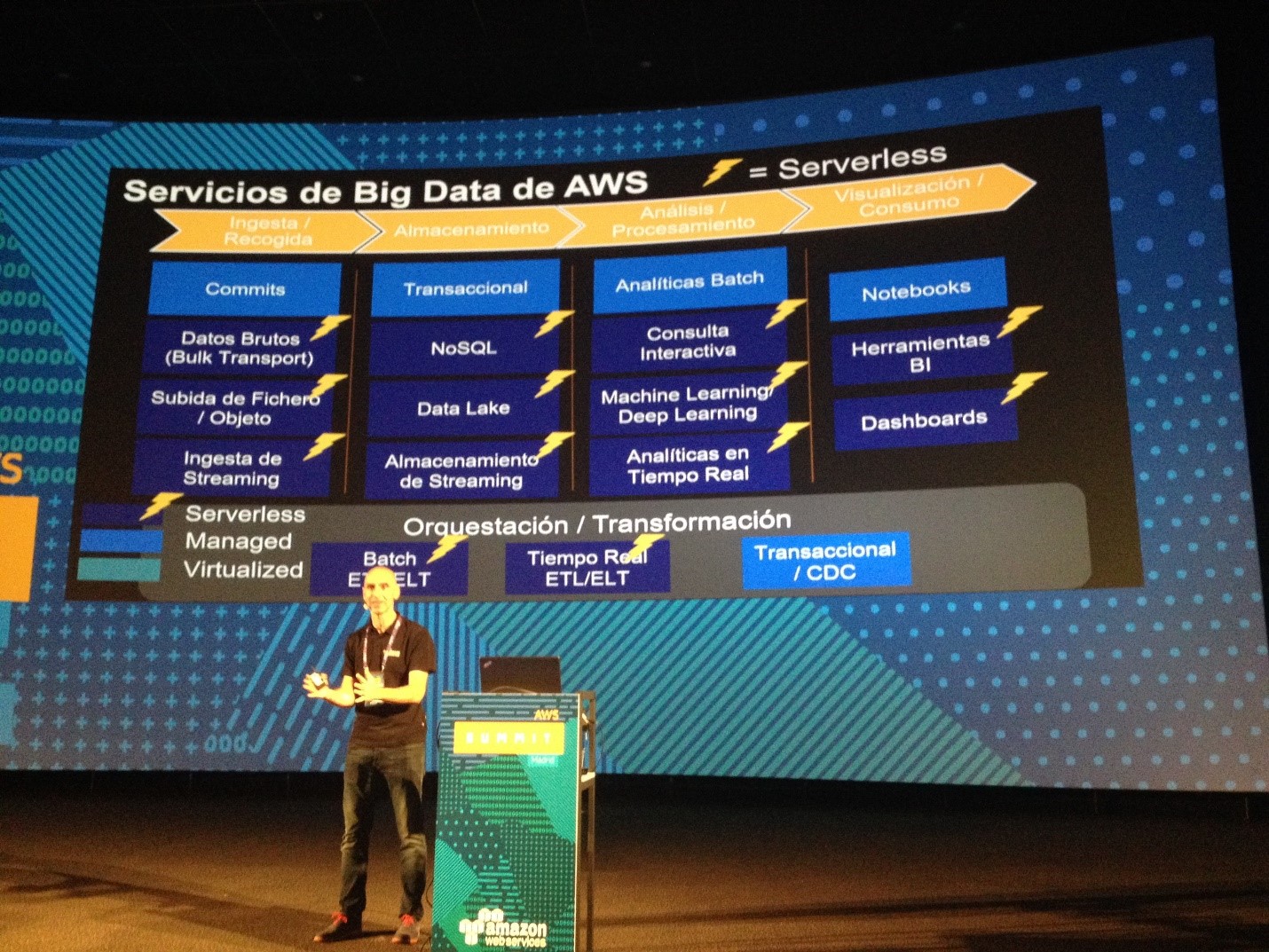
Nel secondo intervento è stata illustrata l’architettura serverless di Big Data, che consente di creare ed eseguire applicazioni e servizi senza doverne gestire l’infrastruttura. Le applicazioni sono comunque eseguite su server, ma la gestione di questi ultimi è a carico di AWS. Non è più necessario allocare, ricalibrare e mantenere server per eseguire applicazioni, database e sistemi di storage.
Nel secondo incontro del pomeriggio sono stati illustrati alcuni strumenti per lo sviluppo di software di IA: Amazon Rekognition, Amazon Polly e Amazon Lex.

Amazon Rekognition è un servizio di riconoscimento delle immagini basato sul Deep Learning. Con Rekognition, è possibile rilevare oggetti, ambienti e volti all’interno delle immagini, identificando celebrità o eventuali contenuti inappropriati. Puoi anche ricercare e mettere a confronto volti. L’API Rekognition consente di aggiungere rapidamente alle applicazioni sofisticate classificazioni di ricerca visiva e immagini basate sull’apprendimento profondo. Amazon Rekognition si basa sulla stessa tecnologia comprovata di apprendimento profondo, altamente scalabile, sviluppata dagli esperti di visione artificiale di Amazon, che permette di analizzare quotidianamente miliardi di immagini per Prime Photos. Amazon Rekognition utilizza modelli di rete neurale profonda per rilevare ed etichettare migliaia di oggetti e scene nelle tue immagini e continua ad aggiungere al servizio nuove etichette e caratteristiche di riconoscimento facciale. L’API Rekognition consente di creare una potente funzionalità di ricerca e scoperta visiva nelle applicazioni. Tale servizio può trovare una giusta collocazione nei seguenti impieghi: controllo legale e sicurezza pubblica, industria alberghiera, retail, marketing digitale, entertainment e media.

Amazon Polly è un servizio che trasforma il testo in una conversazione reale, consentendoti di creare applicazioni che parlano e creare categorie completamente nuove di prodotti con funzionalità vocali. Amazon Polly è un servizio di output vocale che utilizza tecnologie avanzate di apprendimento approfondito per sintetizzare una voce che assomiglia a quella umana. I casi d’uso che questa tecnologia può trovare collocazione sono il sistema educativo, l’accessibilità ad alcuni servizi per coloro che sono portatori di handicap (ad esempio la creazione di audiolibri), la telefonia e i call center, l’IoT e il settore dei videogiochi.

Amazon Lex è un servizio per la creazione di interfacce di comunicazione tramite voce e testo per qualsiasi tipo di applicazione. Amazon Lex offre funzionalità avanzate di apprendimento approfondito per il riconoscimento vocale e la dettatura, nonché per il riconoscimento del linguaggio naturale e la comprensione di testi, consentendo la creazione di applicazioni coinvolgenti e conversazioni realistiche. Con Amazon Lex, le stesse tecnologie di apprendimento approfondito su cui si basa Amazon Alexa sono disponibili a tutti gli sviluppatori, consentendo così la creazione di chatbot sofisticati e naturali in modo semplice e veloce.

